
In this study, researchers build evaluation tasks from naturally-occurring textual resources.
Author: Mingda Chen. Table of Links Abstract Acknowledgements 1 INTRODUCTION 1.1 Overview 1.2 Contributions 2 BACKGROUND 2.1 Self-Supervised Language Pretraining 2.2 Naturally-Occurring Data Structures 2.3 Sentence Variational Autoencoder 2.4 Summary 3 IMPROVING SELF-SUPERVISION FOR LANGUAGE PRETRAINING 3.1 Improving Language Representation Learning via Sentence Ordering Prediction 3.2 Improving In-Context Few-Shot Learning via Self-Supervised Training 3.
are to some extent similar to story generation , the fact that these instances are still constrained by the input tables enables different evaluation approaches and brings new challenges . Because of the range of knowledge-backed generation instances in differs from these datasets in that it is larger in scale and contains multi-sentence texts. More details are in the next section. Wikipedia has also been used to construct datasets for other text generation tasks, such as generating Wikipedia movie plots and short Wikipedia event summaries , and summarizing Wikipedia documents or summaries of aspects of interests from relevant documents.
. Dataset Construction. We begin by describing the steps we take to construct offers more diverse topics than the sportsrelated datasets ROTOWIRE and MLB, or the biography-related dataset WIKIBIO. Compared to the prior work that also uses Wikipedia for constructing datasets, WIKIBIO, LogicNLG, ToTTo, and DART all focus on sentence generation, whereas
do not have these relations or Wikidata entries, and we omit these articles in the table. As the table demonstrates, more than 50% of the articles in are more diverse, including both numbers , and short phrases. This makes . Human Evaluation. We conduct a human evaluation using generations from the large model on the development set. We choose texts shorter than 100 tokens and that cover particular topics as we found during pilot studies that annotators struggled with texts that were very long or about unfamiliar topics. We design two sets of questions. The first focuses on the text itself and its faithfulness to the input article table.
contains millions of instances covering a broad range of topics and a variety of flavors of generation with different levels of flexibility. Fig. 6.1 shows two examples from can be used as a pretraining dataset for other relatively smallscale data-to-text datasets . A similar idea that uses data-to-text generation to create corpora for pretraining language models has shown promising results . In experiments, we train several baseline models on
dataset pairs Wikipedia sections with their corresponding tabular data and various metadata; some of this data is relevant to entire Wikipedia articles or article structure , while some is section-specific . Each data table consists of a set of records , each of which is a tuple containing an attribute and a value . records attribute value The instances in
and related datasets. While the average length of a is also much larger than all existing datasets. Dataset Characteristics. To demonstrate the diversity of topics covered in : 1. In contrast to work on evaluating commonsense knowledge in generation where reference texts are single sentences describing everyday scenes ,
United Kingdom Latest News, United Kingdom Headlines
Similar News:You can also read news stories similar to this one that we have collected from other news sources.
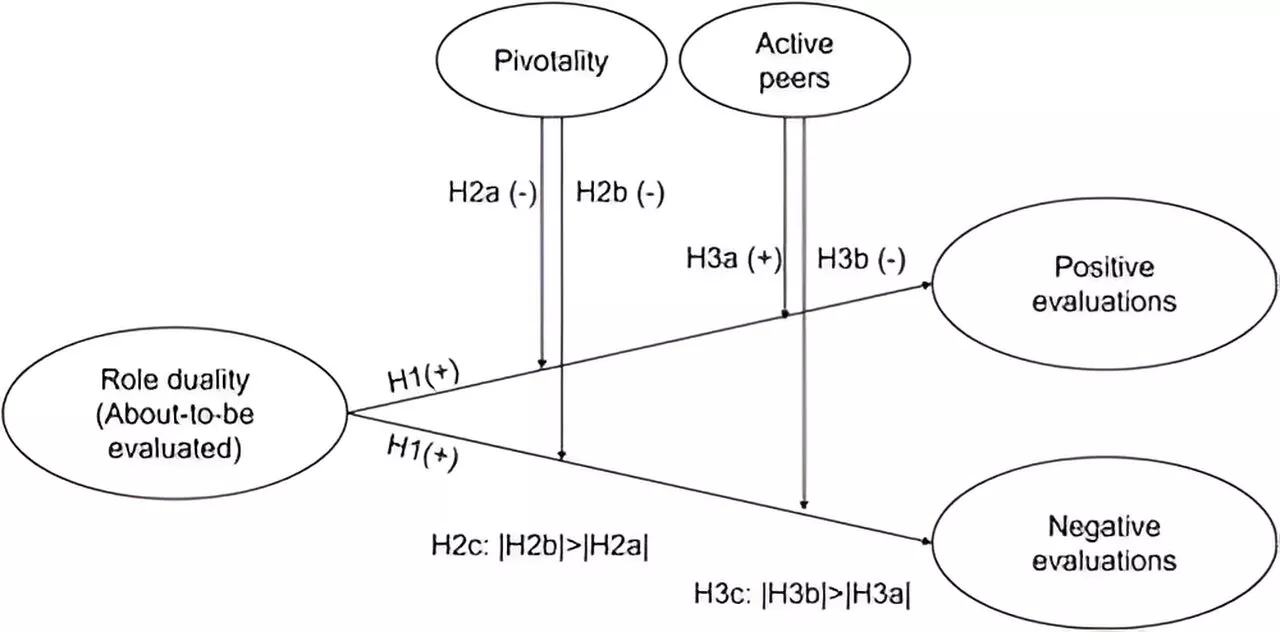 Study finds individuals less likely to evaluate peers negatively if facing evaluation themselvesNew research from ESMT Berlin finds that individuals strategically select the colleagues they evaluate, and the evaluation they give, based on how they want to be perceived. The research was published in the journal Organization Science.
Study finds individuals less likely to evaluate peers negatively if facing evaluation themselvesNew research from ESMT Berlin finds that individuals strategically select the colleagues they evaluate, and the evaluation they give, based on how they want to be perceived. The research was published in the journal Organization Science.
Read more »
 25 Best Petite Jeans for Women 2024 That Don’t Need TailoringOne Vogue editor searches for the best petite jeans for women, from high-rise styles to straight-leg fits. Shop her go-to finds that don’t need alterations.
25 Best Petite Jeans for Women 2024 That Don’t Need TailoringOne Vogue editor searches for the best petite jeans for women, from high-rise styles to straight-leg fits. Shop her go-to finds that don’t need alterations.
Read more »
 Independent evaluation of mental competency granted for accused killer of El Cajon dentistRyan Hill is stoked to be in San Diego! He’s coming to the area from Sacramento. So, he only had to shuffle his area codes around a little bit, trading the 916 for the 619.
Independent evaluation of mental competency granted for accused killer of El Cajon dentistRyan Hill is stoked to be in San Diego! He’s coming to the area from Sacramento. So, he only had to shuffle his area codes around a little bit, trading the 916 for the 619.
Read more »
 End Of Season Evaluation: Jazz SG Jordan ClarksonThe Utah Jazz have a decision to make with their most tenured player
End Of Season Evaluation: Jazz SG Jordan ClarksonThe Utah Jazz have a decision to make with their most tenured player
Read more »
 Evaluation of Project Roomkey finds program had lasting impact on homelessnessAn independent evaluation of Project Roomkey found that 22% of participants moved into permanent housing.
Evaluation of Project Roomkey finds program had lasting impact on homelessnessAn independent evaluation of Project Roomkey found that 22% of participants moved into permanent housing.
Read more »
Highlights & Evaluation: Louisville PF Commit Khani RoothsLouisville Report breaks down 2024 Louisville men's basketball power forward commit Khani Rooths.
Read more »